Tutorial#
!pip install --quiet scvi-colab
from scvi_colab import install
install()
import numpy as np
import pandas as pd
import scanpy as sc
import scvelo as scv
import torch
from velovi import preprocess_data, VELOVI
import matplotlib.pyplot as plt
import seaborn as sns
Load and preprocess data#
adata = scv.datasets.pancreas()
scv.pp.filter_and_normalize(adata, min_shared_counts=30, n_top_genes=2000)
scv.pp.moments(adata, n_pcs=30, n_neighbors=30)
Filtered out 21611 genes that are detected 30 counts (shared).
Normalized count data: X, spliced, unspliced.
Extracted 2000 highly variable genes.
Logarithmized X.
computing neighbors
finished (0:00:03) --> added
'distances' and 'connectivities', weighted adjacency matrices (adata.obsp)
computing moments based on connectivities
finished (0:00:00) --> added
'Ms' and 'Mu', moments of un/spliced abundances (adata.layers)
adata = preprocess_data(adata)
computing velocities
finished (0:00:00) --> added
'velocity', velocity vectors for each individual cell (adata.layers)
Train and apply model#
VELOVI.setup_anndata(adata, spliced_layer="Ms", unspliced_layer="Mu")
vae = VELOVI(adata)
vae.train()
Epoch 405/500: 81%|████████ | 405/500 [01:16<00:17, 5.31it/s, loss=-2.4e+03, v_num=1]
Monitored metric elbo_validation did not improve in the last 45 records. Best score: -2330.793. Signaling Trainer to stop.
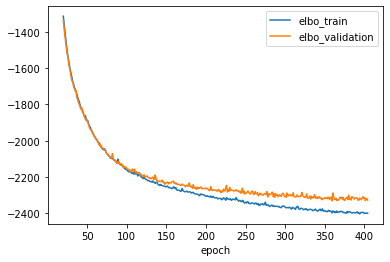
fig, ax = plt.subplots()
vae.history["elbo_train"].iloc[20:].plot(ax=ax, label="train")
vae.history["elbo_validation"].iloc[20:].plot(ax=ax, label="validation")
plt.legend()
<matplotlib.legend.Legend at 0x7f8ddba28d90>
Get model outputs#
def add_velovi_outputs_to_adata(adata, vae):
latent_time = vae.get_latent_time(n_samples=25)
velocities = vae.get_velocity(n_samples=25, velo_statistic="mean")
t = latent_time
scaling = 20 / t.max(0)
adata.layers["velocity"] = velocities / scaling
adata.layers["latent_time_velovi"] = latent_time
adata.var["fit_alpha"] = vae.get_rates()["alpha"] / scaling
adata.var["fit_beta"] = vae.get_rates()["beta"] / scaling
adata.var["fit_gamma"] = vae.get_rates()["gamma"] / scaling
adata.var["fit_t_"] = (
torch.nn.functional.softplus(vae.module.switch_time_unconstr)
.detach()
.cpu()
.numpy()
) * scaling
adata.layers["fit_t"] = latent_time.values * scaling[np.newaxis, :]
adata.var['fit_scaling'] = 1.0
add_velovi_outputs_to_adata(adata, vae)
scv.tl.velocity_graph(adata)
computing velocity graph (using 1/20 cores)
finished (0:00:05) --> added
'velocity_graph', sparse matrix with cosine correlations (adata.uns)
scv.pl.velocity_embedding_stream(adata, basis='umap')
computing velocity embedding
finished (0:00:00) --> added
'velocity_umap', embedded velocity vectors (adata.obsm)

Intrinsic uncertainty#
uncertainty_df, _ = vae.get_directional_uncertainty(n_samples=100)
uncertainty_df.head()
INFO velovi: Sampling from model...
INFO velovi: Computing the uncertainties...
| directional_variance | directional_difference | directional_cosine_sim_variance | directional_cosine_sim_difference | directional_cosine_sim_mean | |
|---|---|---|---|---|---|
| index | |||||
| AAACCTGAGAGGGATA | 0.000992 | 0.099744 | 0.000558 | 0.074686 | 0.663482 |
| AAACCTGAGCCTTGAT | 0.001516 | 0.122854 | 0.000897 | 0.094864 | 0.637474 |
| AAACCTGAGGCAATTA | 0.001124 | 0.108947 | 0.000674 | 0.083901 | 0.639332 |
| AAACCTGCATCATCCC | 0.001043 | 0.103214 | 0.000584 | 0.077158 | 0.664519 |
| AAACCTGGTAAGTGGC | 0.001091 | 0.109103 | 0.000600 | 0.080870 | 0.676792 |
for c in uncertainty_df.columns:
adata.obs[c] = np.log10(uncertainty_df[c].values)
sc.pl.umap(
adata,
color="directional_cosine_sim_variance",
cmap="Greys",
vmin="p1",
vmax="p99",
)

Extrinsic uncertainty#
def compute_extrinisic_uncertainty(adata, vae, n_samples=25) -> pd.DataFrame:
from velovi._model import _compute_directional_statistics_tensor
from scvi.utils import track
from contextlib import redirect_stdout
import io
extrapolated_cells_list = []
for i in track(range(n_samples)):
with io.StringIO() as buf, redirect_stdout(buf):
vkey = "velocities_velovi_{i}".format(i=i)
v = vae.get_velocity(n_samples=1, velo_statistic="mean")
adata.layers[vkey] = v
scv.tl.velocity_graph(adata, vkey=vkey, sqrt_transform=False, approx=True)
t_mat = scv.utils.get_transition_matrix(
adata, vkey=vkey, self_transitions=True, use_negative_cosines=True
)
extrapolated_cells = np.asarray(t_mat @ adata.layers["Ms"])
extrapolated_cells_list.append(extrapolated_cells)
extrapolated_cells = np.stack(extrapolated_cells_list)
df = _compute_directional_statistics_tensor(extrapolated_cells, n_jobs=-1, n_cells=adata.n_obs)
return df
ext_uncertainty_df = compute_extrinisic_uncertainty(adata, vae)
Working...: 0%| | 0/25 [00:00<?, ?it/s]Working...: 4%|▍ | 1/25 [00:01<00:36, 1.53s/it]Working...: 8%|▊ | 2/25 [00:03<00:35, 1.55s/it]Working...: 12%|█▏ | 3/25 [00:04<00:33, 1.54s/it]Working...: 16%|█▌ | 4/25 [00:06<00:32, 1.54s/it]Working...: 20%|██ | 5/25 [00:07<00:31, 1.56s/it]Working...: 24%|██▍ | 6/25 [00:09<00:29, 1.56s/it]Working...: 28%|██▊ | 7/25 [00:10<00:28, 1.56s/it]Working...: 32%|███▏ | 8/25 [00:12<00:26, 1.56s/it]Working...: 36%|███▌ | 9/25 [00:14<00:24, 1.56s/it]Working...: 40%|████ | 10/25 [00:15<00:23, 1.54s/it]Working...: 44%|████▍ | 11/25 [00:17<00:21, 1.55s/it]Working...: 48%|████▊ | 12/25 [00:18<00:20, 1.61s/it]Working...: 52%|█████▏ | 13/25 [00:20<00:18, 1.57s/it]Working...: 56%|█████▌ | 14/25 [00:21<00:17, 1.55s/it]Working...: 60%|██████ | 15/25 [00:23<00:15, 1.53s/it]Working...: 64%|██████▍ | 16/25 [00:24<00:13, 1.51s/it]Working...: 68%|██████▊ | 17/25 [00:26<00:12, 1.50s/it]Working...: 72%|███████▏ | 18/25 [00:27<00:10, 1.50s/it]Working...: 76%|███████▌ | 19/25 [00:29<00:08, 1.50s/it]Working...: 80%|████████ | 20/25 [00:30<00:07, 1.47s/it]Working...: 84%|████████▍ | 21/25 [00:32<00:05, 1.47s/it]Working...: 88%|████████▊ | 22/25 [00:33<00:04, 1.45s/it]Working...: 92%|█████████▏| 23/25 [00:34<00:02, 1.44s/it]Working...: 96%|█████████▌| 24/25 [00:36<00:01, 1.45s/it]Working...: 100%|██████████| 25/25 [00:37<00:00, 1.51s/it]
INFO velovi: Computing the uncertainties...
for c in ext_uncertainty_df.columns:
adata.obs[c + "_extrinisic"] = np.log10(ext_uncertainty_df[c].values)
sc.pl.umap(
adata,
color="directional_cosine_sim_variance_extrinisic",
vmin="p1",
vmax="p99",
)

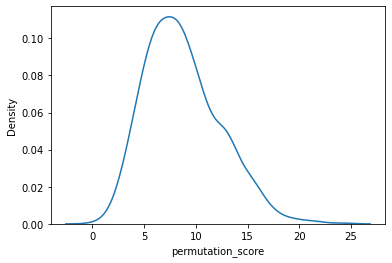
Permutation score#
perm_df, _ = vae.get_permutation_scores(labels_key="clusters")
adata.var["permutation_score"] = perm_df.max(1).values
INFO Input AnnData not setup with scvi-tools. attempting to transfer AnnData setup
INFO Input AnnData not setup with scvi-tools. attempting to transfer AnnData setup
sns.kdeplot(data=adata.var, x="permutation_score")
<AxesSubplot:xlabel='permutation_score', ylabel='Density'>